traffic server 缓存
https://trafficserver.apache.org/
https://github.com/apache/trafficserver
https://cwiki.apache.org/confluence/display/TS/Apache+Traffic+Server
Traffic Server is a fast, scalable and extensible HTTP/1.1 and HTTP/2 compliant caching proxy server. It was formerly a commercial product created by Inktomi and later aquired by Yahoo! in 2002. Yahoo! maintained the source until its open source release in August 2009.
Today Traffic Server is now a top-level project at the Apache Software Foundation.
Ostatic.com featured an overview of Traffic Server written by Yahoo!’s Cloud Computing team.
futures:
-
Caching Improve your response time, while reducing server load and bandwidth needs by caching and reusing frequently-requested web pages, images, and web service calls.
-
Proxying Easily add keep-alive, filter or anonymize content requests, or add load balancing by adding a proxy layer.
-
Fast Scales well on modern SMP hardware, handling 10s of thousands of requests per second.
-
Extensible APIs to write your own plug-ins to do anything from modifying HTTP headers to handling ESI requests to writing your own cache algorithm.
-
Proven Handling over 400TB a day at Yahoo! both as forward and reverse proxies, Apache Traffic Server is battle hardened. Also visit our Customers page for some of our corporate users and supporters.
HTTP Proxy Caching
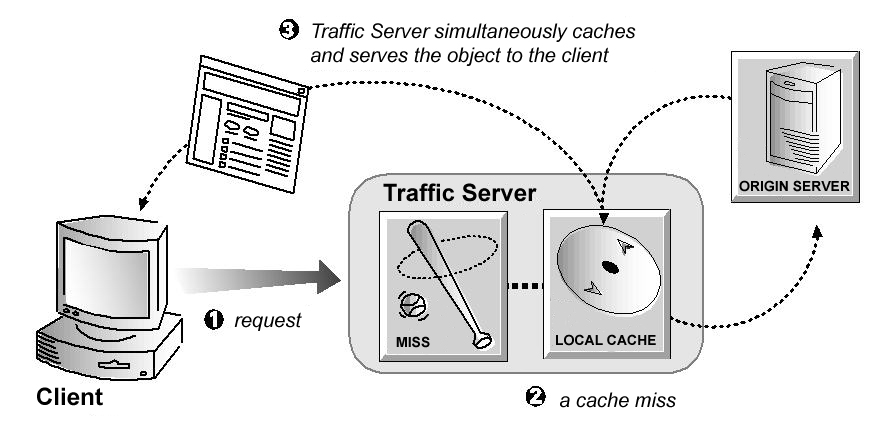
object store. The Traffic Server cache consists of a high-speed object database called the object store that indexes cache objects according to URLs and their associated headers.
- indexes urls headers
- remove stale data
futures:
- Ensuring Cached Object Freshness. author-specified expiration dates. Expires header or max-age header. freshness_limit = ( date - last_modified ) * 0.10.
- Modifying Aging Factor for Freshness Computations
- Revalidating HTTP Objects
- Pushing Content into the Cache
- treats requests for objects that cannot or should not be cached
HTTP/1.0/1.1/2.0
HTTP/2.0 相比1.0有哪些重大改进? https://www.zhihu.com/question/34074946
HTTP 2.0与HTTP 1.1区别
HTTP2与HTTP1.1的区别 http://blog.csdn.net/xiongyk/article/details/52443696
WebSocket 是什么原理?为什么可以实现持久连接? https://www.zhihu.com/question/20215561
HTTP/2.0 相比1.0:
- 1.HTTP2使用的是二进制传送,HTTP1.X是文本(字符串)传送。 大家都知道HTTP1.X使用的是明文的文本传送,而HTTP2使用的是二进制传送,二进制传送的单位是帧和流。帧组成了流,同时流还有流ID标示,通过流ID就牵扯出了第二个区别
- 2.HTTP2支持多路复用 因为有流ID,所以通过同一个http请求实现多个http请求传输变成了可能,可以通过流ID来标示究竟是哪个流从而定位到是哪个http请求
- 3.HTTP2头部压缩 HTTP2通过gzip和compress压缩头部然后再发送,同时客户端和服务器端同时维护一张头信息表,所有字段都记录在这张表中,这样后面每次传输只需要传输表里面的索引Id就行,通过索引ID就可以知道表头的值了
- 4.HTTP2支持服务器推送 HTTP2支持在客户端未经请求许可的情况下,主动向客户端推送内容
HTTP协议详解 https://www.cnblogs.com/EricaMIN1987_IT/p/3837436.html
HTTP协议的主要特点可概括如下:
- 1、支持客户/服务器模式。支持基本认证和安全认证。
- 2、简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法- 规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
- 3、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- 4、HTTP 0.9和1.0使用非持续连接:限制每次连接只处理一个请求,服务器处理完客户的请求,并收到客户的应答后- ,即断开连接。HTTP 1.1使用持续连接:不必为每个web对象创建一个新的连接,一个连接可以传送多个对象,采用- 这种方式可以节省传输时间。
- 5、无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。
解决HTTP无状态的问题:
- 通过Cookies保存状态信息
- 通过Session保存状态信息 服务器端的机制
深入理解HTTP1.0和HTTP1.1的区别 https://www.jianshu.com/p/95a521b006a8
HTTP1.0和HTTP1.1的区别:
- 长连接(PersistentConnection) Connection请求头的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接。HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。
- 流水线(Pipelining)在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。 HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容。
- host字段 在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
- 100(Continue) Status 允许客户端在发request消息body之前先用request header试探一下server,看server要不要接收request body,再决定要不要发request body。
- Chunked transfer-coding HTTP/1.1中引入了Chunked transfer-coding来解决上面这个问题,发送方将消息分割成若干个任意大小的数据块,每个数据块在发送时都会附上块的长度,最后用一个零长度的块作为消息结束的标志。这种方法允许发送方只缓冲消息的一个片段,避免缓冲整个消息带来的过载。
- chache HTTP/1.1在1.0的基础上加入了一些cache的新特性,当缓存对象的Age超过Expire时变为stale对象,cache不需要直接抛弃stale对象,而是与源服务器进行重新激活(revalidation)。
http1.1 header
chrome -> 开发者工具 -> network->选name->Headers
GET / HTTP/1.1
Host: trafficserver.apache.org
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
HTTP/1.1 200 OK
Date: Wed, 07 Feb 2018 06:38:57 GMT
Server: Apache/2.4.7 (Ubuntu)
Content-Location: index.html
Vary: negotiate,Accept-Encoding
TCN: choice
Accept-Ranges: bytes
Content-Encoding: gzip
Content-Length: 4427
Keep-Alive: timeout=30, max=100
Connection: Keep-Alive
Content-Type: text/html
缓存的实现原理
WEB缓存(cache)位于Web服务器和客户端之间。 缓存会根据请求保存输出内容的副本,例如html页面,图片,文件,当下一个请求来到的时候:如果是相同的URL,缓存直接使用副本响应访问请求,而不是向源服务器再次发送请求。 HTTP协议定义了相关的消息头来使WEB缓存尽可能好的工作。
10.1、缓存的优点 减少相应延迟:因为请求从缓存服务器(离客户端更近)而不是源服务器被相应,这个过程耗时更少,让web服务器看上去相应更快。 减少网络带宽消耗:当副本被重用时会减低客户端的带宽消耗;客户可以节省带宽费用,控制带宽的需求的增长并更易于管理。
10.2、客户端缓存生效的常见流程
服务器收到请求时,会在200OK中回送该资源的Last-Modified和ETag头,客户端将该资源保存在cache中,并记录这两个属性。当客户端需要发送相同的请求时,会在请求中携带If-Modified-Since和If-None-Match两个头。两个头的值分别是响应中Last-Modified和ETag头的值。服务器通过这两个头判断本地资源未发生变化,客户端不需要重新下载,返回304响应。
10.3、Web缓存机制
HTTP/1.1中缓存的目的是为了在很多情况下减少发送请求,同时在许多情况下可以不需要发送完整响应。前者减少了网络回路的数量;HTTP利用一个“过期(expiration)”机制来为此目的。后者减少了网络应用的带宽;HTTP用“验证(validation)”机制来为此目的。 HTTP定义了3种缓存机制: 1)Freshness:允许一个回应消息可以在源服务器不被重新检查,并且可以由服务器和客户端来控制。例如,Expires回应头给了一个文档不可用的时间。Cache-Control中的max-age标识指明了缓存的最长时间; 2)Validation:用来检查以一个缓存的回应是否仍然可用。例如,如果一个回应有一个Last-Modified回应头,缓存能够使用If-Modified-Since来判断是否已改变,以便判断根据情况发送请求; 3)Invalidation:在另一个请求通过缓存的时候,常常有一个副作用。例如,如果一个URL关联到一个缓存回应,但是其后跟着POST、PUT和DELETE的请求的话,缓存就会过期。
Session会话
Session的实现方式:
- 1、使用Cookie来实现 服务器给每个Session分配一个唯一的JSESSIONID,并通过Cookie发送给客户端。 当客户端发起新的请求的时候,将在Cookie头中携带这个JSESSIONID。这样服务器能够找到这个客户端对应的Session。
- 2、使用URL回写来实现 URL回写是指服务器在发送给浏览器页面的所有链接中都携带JSESSIONID的参数,这样客户端点击任何一个链接都会把JSESSIONID带会服务器。如果直接在浏览器输入服务端资源的url来请求该资源,那么Session是匹配不到的。Tomcat对Session的实现,是一开始同时使用Cookie和URL回写机制,如果发现客户端支持Cookie,就继续使用Cookie,停止使用URL回写。如果发现Cookie被禁用,就一直使用URL回写。jsp开发处理到Session的时候,对页面中的链接记得使用response.encodeURL() 。
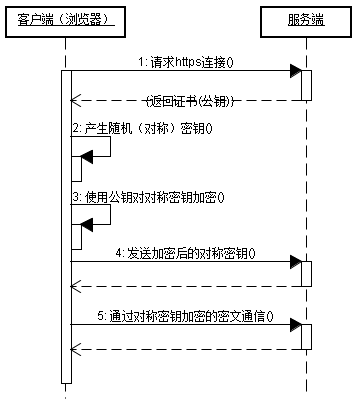
HTTPS